Note
Go to the end to download the full example code.
PCA/PCovR Visualization of a training dataset for a potential¶
- Authors:
Michele Ceriotti @ceriottm, Giulio Imbalzano
This example uses featomic and metatensor to compute
structural properties for the structures in a training dataset
for a ML potential.
These are then used with simple dimensionality reduction algorithms
(implemented in sklearn and skmatter) to obtain a simplified
description of the dataset, that is then visualized using
chemiscope.
This example uses the dataset from Imbalzano (2021) and the principal covariate regression scheme as implemented in Helfrecht (2020).
# sphinx_gallery_thumbnail_number = 2
import ase
import ase.io
import chemiscope
import numpy as np
from atomistic_cookbook_utils import download_with_retry
from featomic import AtomicComposition, SoapPowerSpectrum
from matplotlib import pyplot as plt
from metatensor import mean_over_samples
from sklearn.decomposition import PCA
from sklearn.linear_model import RidgeCV
from skmatter.decomposition import PCovR
from skmatter.preprocessing import StandardFlexibleScaler
First, we load the structures, extracting some of the properties for more convenient manipulation. These are \(\mathrm{Ga}_x\mathrm{As}_{1-x}\) structures used in Imbalzano & Ceriotti (2021) to train a ML potential to describe the full composition range.
filename = "gaas_training.xyz"
download_with_retry(
"https://zenodo.org/records/10566825/files/gaas_training.xyz", filename
)
structures = ase.io.read(filename, ":")
energy = np.array([f.info["energy"] for f in structures])
natoms = np.array([len(f) for f in structures])
Remove atomic energy baseline¶
Energies from an electronic structure calculation contain a very large “self” contributions from the atoms, which can obscure the important differences in cohesive energies between structures. We can build an approximate model based on the chemical nature of the atoms, \(a_i\)
where \(e_a\) are atomic energies that can be determined by linear regression.
# featomic has an `AtomicComposition` calculator that streamlines
# this (simple) calculation
calculator = AtomicComposition(**{"per_system": True})
rho0 = calculator.compute(structures)
# the descriptors are returned as a `TensorMap` object, that contains
# the composition data in a sparse storage format
rho0
# for easier manipulation, we extract the features as a dense vector
# of composition weights
comp_feats = rho0.keys_to_properties(["center_type"]).block(0).values
# a one-liner to fit a linear model and compute "dressed energies"
atom_energy = (
RidgeCV(alphas=np.geomspace(1e-8, 1e2, 20))
.fit(comp_feats, energy)
.predict(comp_feats)
)
cohesive_peratom = (energy - atom_energy) / natoms
The baseline makes up a large fraction of the total energy, but actually the residual (which is the part that matters) is still large.
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
ax.plot(energy / natoms, atom_energy / natoms, "b.")
ax.set_xlabel("Energy / (eV/atom)")
ax.set_ylabel("Atomic e. / (eV/atom)")
plt.show()
print(f"RMSE / (eV/atom): {np.sqrt(np.mean((cohesive_peratom) ** 2))}")
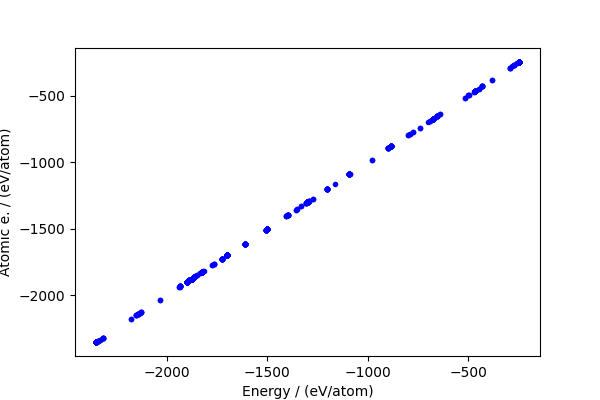
RMSE / (eV/atom): 0.25095782684763684
Compute structural descriptors¶
In order to visualize the structures as a low-dimensional map, we start
by computing suitable ML descriptors. Here we have used featomic to
evaluate average SOAP features for the structures.
# hypers for evaluating features
hypers = {
"cutoff": {"radius": 4.5, "smoothing": {"type": "ShiftedCosine", "width": 0.5}},
"density": {"type": "Gaussian", "width": 0.3},
"basis": {
"type": "TensorProduct",
"max_angular": 4,
"radial": {"type": "Gto", "max_radial": 5},
},
}
calculator = SoapPowerSpectrum(**hypers)
rho2i = calculator.compute(structures)
# neighbor types go to the keys for sparsity (this way one can
# compute a heterogeneous dataset without having blocks of zeros)
rho2i = rho2i.keys_to_samples(["center_type"]).keys_to_properties(
["neighbor_1_type", "neighbor_2_type"]
)
# computes structure-level descriptors and then extracts
# the features as a dense array
rho2i_structure = mean_over_samples(rho2i, sample_names=["atom", "center_type"])
rho2i = None # releases memory
features = rho2i_structure.block(0).values
We standardize (per atom) energy and features (computed as a mean over atomic environments) so that they can be combined on the same footings.
sf_energy = StandardFlexibleScaler().fit_transform(cohesive_peratom.reshape(-1, 1))
sf_feats = StandardFlexibleScaler().fit_transform(features)
PCA and PCovR projection¶
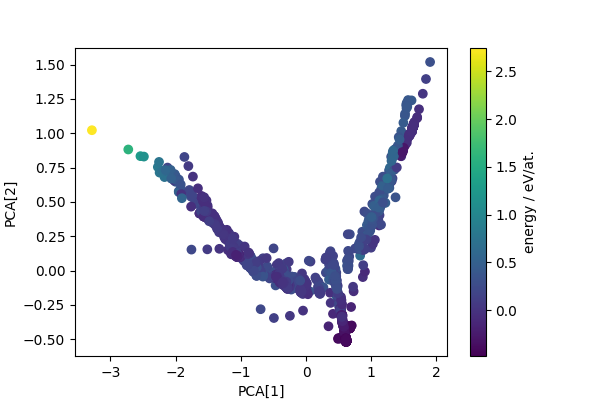
Computes PCA projection to generate low-dimensional descriptors that reflect structural diversity. Any other dimensionality reduction scheme could be used in a similar fashion.
pca = PCA(n_components=4)
pca_features = pca.fit_transform(sf_feats)
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
scatter = ax.scatter(pca_features[:, 0], pca_features[:, 1], c=cohesive_peratom)
ax.set_xlabel("PCA[1]")
ax.set_ylabel("PCA[2]")
cbar = fig.colorbar(scatter, ax=ax)
cbar.set_label("energy / eV/at.")
plt.show()
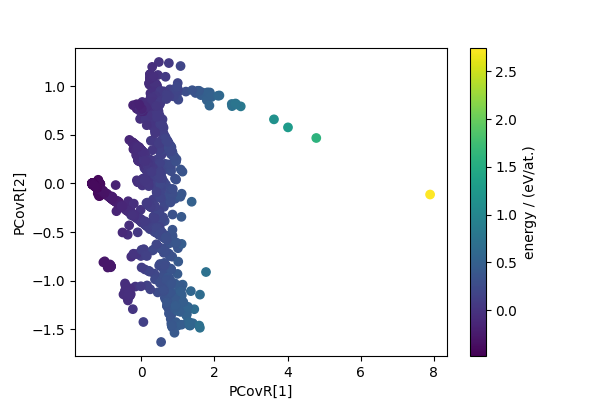
We also compute the principal covariate regression (PCovR) descriptors, that reduce dimensionality while combining a variance preserving criterion with the requirement that the low-dimensional features are capable of estimating a target quantity (here, the energy).
pcovr = PCovR(n_components=4)
pcovr_features = pcovr.fit_transform(sf_feats, sf_energy)
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
scatter = ax.scatter(pcovr_features[:, 0], pcovr_features[:, 1], c=cohesive_peratom)
ax.set_xlabel("PCovR[1]")
ax.set_ylabel("PCovR[2]")
cbar = fig.colorbar(scatter, ax=ax)
cbar.set_label("energy / (eV/at.)")
plt.show()
Chemiscope visualization¶
Visualizes the structure-property map using a chemiscope widget (and generates a .json file that can be viewed on chemiscope.org).
# extracts force data (adding considerably to the dataset size...)
force_vectors = chemiscope.ase_vectors_to_arrows(structures, key="forces", scale=1)
force_vectors["parameters"]["global"]["color"] = 0x505050
# adds properties to the ASE frames
for i, f in enumerate(structures):
for j in range(len(pca_features[i])):
f.info["pca_" + str(j + 1)] = pca_features[i, j]
for i, f in enumerate(structures):
for j in range(len(pcovr_features[i])):
f.info["pcovr_" + str(j + 1)] = pcovr_features[i, j]
for i, f in enumerate(structures):
f.info["cohesive_energy"] = cohesive_peratom[i]
f.info["x_ga"] = comp_feats[i, 0] / comp_feats[i].sum()
# it would also be easy to add the properties manually, this is just a dictionary
structure_properties = chemiscope.extract_properties(structures)
cs = chemiscope.show(
structures=structures,
properties=structure_properties,
shapes={"forces": force_vectors},
# the settings are a tad verbose, but give full control over the visualization
settings={
"map": {
"x": {"property": "pcovr_1"},
"y": {"property": "pcovr_2"},
"color": {"property": "x_ga"},
},
"structure": [
{
"bonds": True,
"unitCell": True,
"shape": ["forces"],
"keepOrientation": False,
}
],
},
meta={
"name": "GaAs training data",
"description": """
A collection of Ga(x)As(1-x) structures to train a MLIP,
including force and energy data.
""",
"authors": ["Giulio Imbalzano", "Michele Ceriotti"],
"references": [
"""
G. Imbalzano and M. Ceriotti, 'Modeling the Ga/As binary system across
temperatures and compositions from first principles,'
Phys. Rev. Materials 5(6), 063804 (2021).
""",
"Original dataset: https://archive.materialscloud.org/record/2021.226",
],
},
)
cs.save("gaas_map.chemiscope.json.gz")
cs # display if in a notebook

/home/runner/work/atomistic-cookbook/atomistic-cookbook/examples/gaas-map/gaas-map.py:214: UserWarning: `meta` argument is deprecated, use `metadata` instead
cs = chemiscope.show(
Total running time of the script: (1 minutes 51.156 seconds)